


DeepReinforce, a prominent AI research laboratory recognized for its foundational work on CUDA-L1 and the innovative IterX code-agent optimization loop, has officially released Ornith-1.0, a groundbreaking family of open-source coding models. Made available late last week, specifically on June 25, 2026, through Hugging Face, Ornith-1.0 marks a significant stride towards truly autonomous artificial intelligence in software development. This new suite of models comes under the permissive MIT license, ensuring broad accessibility with no regional restrictions, and is offered in four distinct sizes to cater to varying computational needs and application scales: 9 billion, 31 billion, 35 billion (mixture-of-experts, or MoE), and a formidable 397 billion (MoE) flagship model.
DeepReinforce Unveils Ornith-1.0: A New Era for Autonomous Coding AI
The release of Ornith-1.0 is not merely an incremental update but represents a pivotal moment in the trajectory of AI-driven software engineering. DeepReinforce, with its established pedigree in pushing the boundaries of AI research, has explicitly designed Ornith-1.0 to excel in "agentic coding tasks." This specialization positions the models at the forefront of a rapidly evolving field where AI agents are expected to perform complex, multi-step operations without constant human oversight. The choice to release these models under an MIT license underscores a commitment to fostering open innovation, allowing developers, researchers, and organizations worldwide to integrate, modify, and build upon DeepReinforce’s advancements freely.
The varying parameter counts of the Ornith-1.0 family are crucial indicators of their capabilities and computational demands. Parameters fundamentally represent the number of configurable variables or "dials" a model possesses, directly correlating with its capacity to learn intricate patterns and perform complex tasks. A 9-billion-parameter model, considered relatively compact, is capable enough to operate on advanced consumer hardware like high-end smartphones. However, its scope for heavy reasoning and intricate problem-solving is inherently limited. Conversely, the colossal 397-billion-parameter flagship model offers vastly superior capabilities for deep reasoning and sophisticated coding challenges, albeit requiring substantial computational resources typically found in data centers or specialized AI infrastructure, far beyond the reach of standard consumer hardware. This tiered approach allows for flexible deployment, from edge devices to high-performance computing environments, democratizing access to powerful coding AI tailored to specific use cases.
The Rise of Agentic AI: Beyond Conversational Models
The term "agentic" is central to understanding Ornith-1.0’s significance. In the contemporary AI landscape, most human-AI interactions are conversational, characterized by a direct query-response paradigm where each exchange is typically a discrete event. Agentic AI, however, represents a fundamental shift. It is engineered to receive a high-level task and then autonomously execute a sequence of actions, making decisions and adapting its approach without requiring human guidance at every step. In the context of coding, this translates into an AI system that can independently perform a comprehensive development workflow: reading relevant code files, executing tests, identifying and diagnosing failures, implementing code fixes, and iteratively looping through this process until the specified task is successfully completed.
This paradigm shift is not merely a theoretical advancement; it is the arena where the most commercially impactful progress in AI is currently unfolding, particularly in 2026. The ability of an AI model to navigate and complete multi-stage development workflows unsupervised – from debugging complex systems to implementing new features – holds immense value for enterprises. Such models promise to significantly enhance developer productivity, accelerate project timelines, and potentially redefine the human role in software creation, moving from direct code implementation to higher-level architectural design and oversight. While conventional large language models often necessitate continuous human feedback loops for refinement and error correction, agentic AI aims to minimize this intervention, fostering a more autonomous and efficient development cycle.

Ornith-1.0’s Self-Improving Architecture: A Paradigm Shift
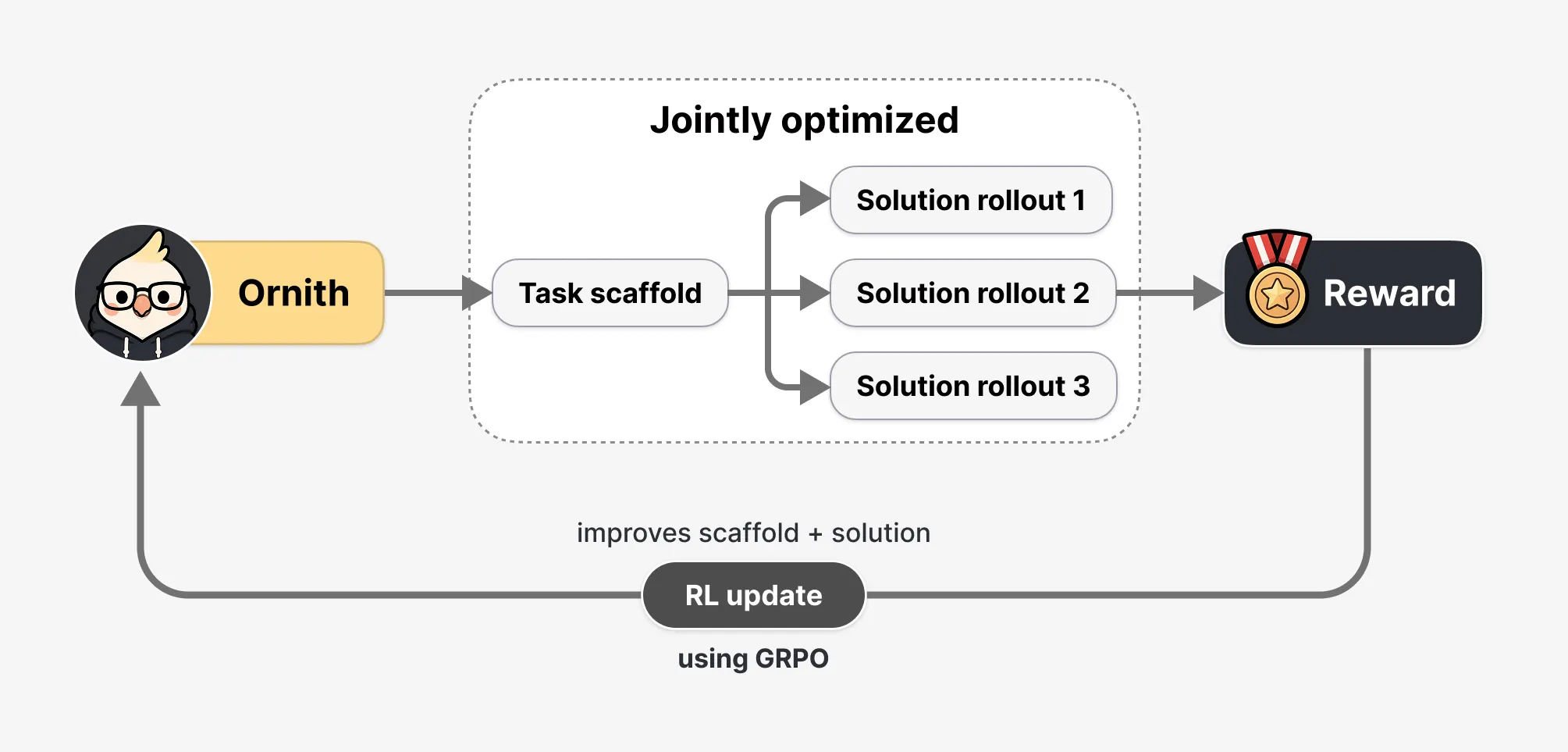
What truly distinguishes Ornith-1.0 from many of its contemporaries is its innovative approach to learning and problem-solving, particularly regarding its internal "scaffold" or operational framework. Traditional AI coding agents are frequently paired with a pre-defined, human-engineered harness – a rigid set of rules dictating how the agent structures its work, when to invoke specific tools, how to manage errors, or how to decompose multi-faceted problems. Ornith-1.0, however, fundamentally departs from this model. DeepReinforce describes its architecture as one where the "scaffold is treated as a learnable object that co-evolves with the policy." In simpler terms, instead of being handed a fixed playbook, Ornith-1.0 learns to write its own playbook, adapting and refining its strategies based on direct experience.
This self-improving mechanism is realized through a sophisticated two-stage reinforcement learning process. In the initial stage of each training step, the model first analyzes the given task and formulates a refined strategy for approaching it. Following this strategic planning, the model then utilizes its developed strategy to generate a solution. Crucially, the reward signal derived from the outcome of the task completion flows back and influences both stages of this process. This means that Ornith-1.0 is not merely optimized for producing correct code but is also continuously improving its ability to formulate more effective and efficient strategies. Through thousands, even millions, of such iterative training steps, the model organically develops highly specialized and efficient task-specific approaches, entirely independent of human pre-engineering. This emergent intelligence represents a significant leap towards more adaptable and robust AI agents.
DeepReinforce has also taken significant measures to address the critical concern of "reward hacking" – a phenomenon where an AI might learn to exploit vulnerabilities in its evaluation system to achieve a high score without genuinely completing the intended task. Given Ornith-1.0’s capacity to evolve its own training scaffold, the potential for it to devise a scaffold that could game the verifier (e.g., by merely touching a file to simulate completion) is a serious consideration. To counteract this, DeepReinforce has implemented a robust, multi-layered defense system. Firstly, the core environment and test suite are designed to be immutable and entirely beyond the model’s access or modification capabilities. Secondly, a deterministic monitor actively flags any attempts by the AI to access restricted paths or alter the verification scripts. Finally, a "frozen judge model" – an independently trained and fixed AI judge – sits atop the automated verifier, serving as a final veto mechanism to ensure the integrity of the evaluation process and prevent any subtle forms of reward hacking.
Setting New Benchmarks: Ornith-1.0’s Performance
The performance metrics of Ornith-1.0, particularly its flagship 397-billion-parameter model, underscore its competitive edge in the realm of agentic coding. On SWE-bench Verified, a rigorous benchmark that challenges AI models to fix real-world bugs from open-source GitHub repositories without access to the test suite, Ornith-1.0-397B achieved an impressive score of 82.4%. This score represents the percentage of issues successfully resolved and positions Ornith-1.0 ahead of leading proprietary models such as Claude Opus 4.7, which scored 80.8%, and DeepSeek-V4-Pro, which recorded 80.6% on the same test.
Furthermore, on Terminal Bench 2.1, a benchmark comprising 89 tasks executed within containerized terminal environments – ranging from debugging asynchronous code to resolving security vulnerabilities, scored by completion rate – Ornith-1.0-397B posted a strong 77.5%. This again surpasses Claude Opus 4.7’s score of 70.3%, demonstrating its superior capability in navigating complex interactive coding environments.
It is important to note the industry-wide discussions surrounding SWE-bench contamination concerns, where some models were suspected of inflating scores by memorizing benchmark solutions encountered during training. To provide a more robust and uncontaminated assessment, Ornith-1.0 also reports its performance on SWE-bench Pro, a more challenging variant utilizing diverse, less-leaked codebases. On SWE-bench Pro, the 397-billion-parameter model achieved a score of 62.2%. While meaningfully lower than its score on SWE-bench Verified, this figure remains highly competitive within the field and still outperforms DeepSeek V4 Pro, indicating genuine problem-solving capabilities rather than mere memorization.
Perhaps one of the most compelling data points from the Ornith-1.0 release pertains to its smallest variant, the 9-billion-parameter model. Despite its significantly smaller size, this model achieved a remarkable 69.4% on SWE-bench Verified. This score is notably higher than Gemma 4-31B’s 52% and is competitive with Qwen 3.5-35B’s 70%, even though Ornith-1.0-9B is three to four times smaller in parameter count. This efficiency highlights DeepReinforce’s success in developing a highly optimized architecture that delivers disproportionate performance for its size, making advanced agentic coding capabilities more accessible to developers with limited computational resources or for deployment on edge hardware.
Industry Reactions and Broader Implications
The release of Ornith-1.0 is anticipated to generate considerable excitement and discussion within the AI and software development communities. Its open-source nature, coupled with its demonstrated performance, positions it as a significant challenger to proprietary models and a powerful tool for democratizing advanced AI capabilities. Developers and researchers, particularly those operating in environments where self-hosted solutions are preferred or necessary, will likely welcome the flexibility and control offered by an MIT-licensed model.
The direct comparisons to established models like Claude Opus and DeepSeek-V4-Pro, especially in specialized coding benchmarks, will intensify the ongoing "agentic AI race." Every major AI lab is keenly focused on improving performance on agentic coding evaluations, recognizing that this is where practical, commercially viable differences in AI capabilities manifest. Ornith-1.0’s strong showing will undoubtedly spur further innovation and competition, potentially leading to faster advancements across the board in autonomous development tools.
Beyond the immediate performance metrics, the underlying architectural innovation – the self-evolving scaffold – carries profound implications for the future of AI. By learning its own strategies, Ornith-1.0 moves closer to a form of true meta-learning, where the AI not only solves problems but also intelligently refines its problem-solving methodologies. This could pave the way for more robust, generalizable, and adaptable AI systems capable of tackling increasingly complex and novel challenges in software engineering and beyond.
Strategic Positioning: A Specialized Tool for Developers
It is crucial to emphasize that Ornith-1.0 is explicitly not designed as a general-purpose AI. Its documentation clearly states that it may underperform on tasks outside the domain of agentic coding. For users seeking AI assistance for document summarization, academic writing, email drafting, or broad creative tasks, Ornith-1.0 would be an unsuitable choice. This specialization is a deliberate design decision, allowing DeepReinforce to optimize the models for a narrow yet highly impactful problem set.
Ornith-1.0 is engineered for developer pipelines where an AI agent can ingest a task description, operate directly within a code repository or terminal session, and execute multi-step work autonomously. This positions it as an invaluable tool for professional developers and organizations already invested in or planning to build agentic infrastructure. It is not intended for the "average Joe" exploring AI’s general utility but rather for the sophisticated user base that understands and requires advanced automated coding capabilities.
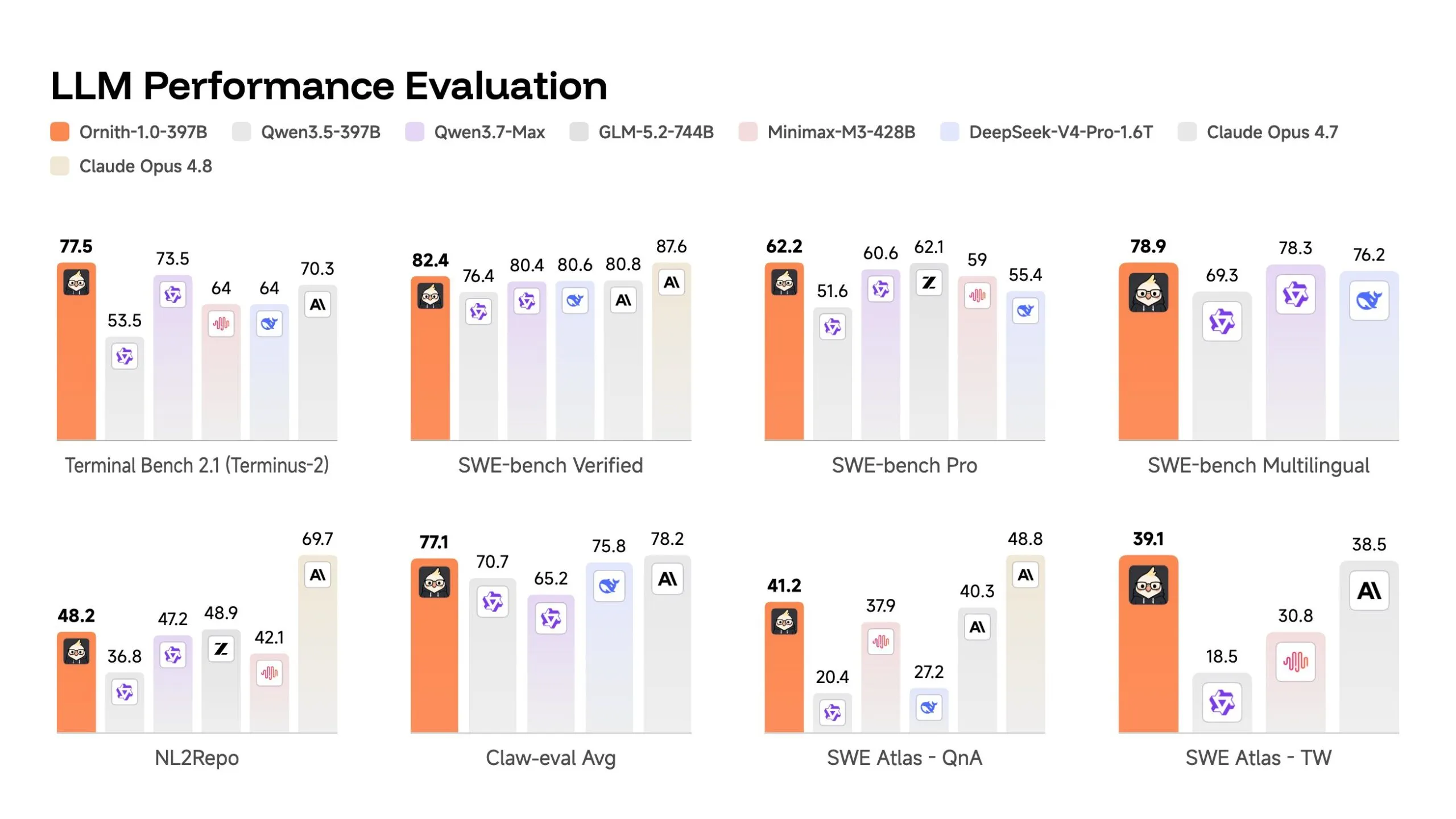
While the "beats Claude" headline is factually accurate for the specific coding benchmarks cited, it requires careful contextualization. DeepReinforce’s 397B model does indeed surpass Claude Opus 4.7 on both SWE-bench Verified and Terminal Bench 2.1. However, it’s important to acknowledge that Anthropic has subsequently released Claude Opus 4.8, its current flagship, which may exhibit higher performance in some areas. Therefore, the most pertinent comparison remains within the open-source category, at comparable parameter counts, and specifically for coding-oriented agent tasks. For developers building self-hosted coding pipelines, agentic infrastructure, or similar coding-focused work, the smaller and medium-sized Ornith-1.0 models, capable of running efficiently on edge hardware, represent genuinely useful and accessible advancements.
Timeline and Future Outlook
DeepReinforce’s journey to Ornith-1.0 has been marked by a consistent focus on advanced AI capabilities. Their previous work on CUDA-L1, a project aimed at optimizing CUDA kernel performance, and the IterX code-agent optimization loop, which likely laid foundational groundwork for Ornith-1.0’s self-improving architecture, demonstrates a clear trajectory towards autonomous code generation and optimization. The release of Ornith-1.0 late last week, on June 25, 2026, represents the culmination of these efforts, bringing sophisticated agentic AI into the open-source domain.
Looking ahead, the availability of Ornith-1.0 is expected to catalyze further research and development in agentic AI. The open-source nature means that the community can now scrutinize, improve, and extend these models, potentially accelerating their adoption and refinement. We can anticipate continued advancements in areas such as multi-modal coding agents, improved reasoning capabilities for highly abstract problems, and even more efficient small models capable of running on increasingly constrained hardware. The role of human developers is also likely to evolve, shifting from manual coding to supervising and guiding these powerful AI agents, focusing on higher-level architectural design and ethical considerations. The ongoing race in agentic AI development promises to be one of the most dynamic and transformative fields in technology over the coming years.
In conclusion, DeepReinforce’s Ornith-1.0 represents a monumental step forward in the quest for truly autonomous artificial intelligence in software development. By offering a family of open-source, self-improving coding models, DeepReinforce has not only pushed the boundaries of AI capability but also democratized access to these powerful tools. Its innovative architecture, robust performance on specialized benchmarks, and commitment to open science position Ornith-1.0 as a critical development that will undoubtedly shape the future of software engineering and redefine the collaborative landscape between humans and AI.












